Modern Datalakes with Hudi, MinIO, and HMS


Apache Hudi has established itself as one of the leading open table formats for managing modern datalakes, offering core warehouse and database functionalities directly within the modern datalake. This is in large part due to Hudi providing advanced features like tables, transactions, upserts/deletes, advanced indexes, streaming ingestion services, data clustering/compaction optimizations and concurrency control.
We’ve already explored how MinIO and Hudi can work together to build a modern datalake. This blog post aims to build on that knowledge and offer an alternative implementation of Hudi and MinIO that leverages Hive Metastore Service (HMS). In part from its origin story arising from the Hadoop ecosystem, many large-scale data implementations of Hudi still leverage HMS. Often a migration story from legacy systems involves some level of hybridization as the best of all of the products involved are leveraged for success.
Hudi on MinIO: A Winning Combination
Hudi's evolution from HDFS dependence to cloud-native object storage like MinIO aligns perfectly with the data industry's shift away from monolithic and inappropriate legacy solutions. MinIO's performance, scalability, and cost-effectiveness make it an ideal choice for storing and managing Hudi data. Additionally, Hudi's optimizations for Apache Spark, Flink, Presto, Trino, StarRocks and others in the modern data seamlessly integrate with MinIO for cloud-native performance at scale. This compatibility represents an important pattern in modern datalake architectures.
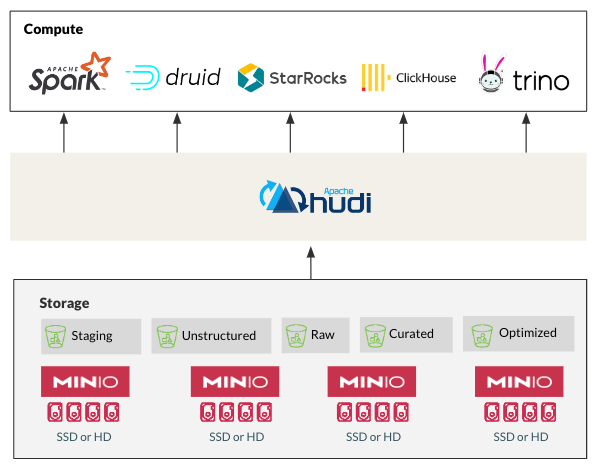
HMS Integration: Enhanced Data Governance and Management
While Hudi provides core data management features out of the box, integrating with HMS adds another layer of control and visibility. Here's how HMS integration benefits large-scale Hudi deployments:
- Improved Data Governance: HMS centralizes metadata management, enabling consistent access control, lineage tracking, and auditing across your data lake. This ensures data quality, compliance, and simplifies governance processes.
- Simplified Schema Management: Define and enforce schemas for Hudi tables within HMS, ensuring data consistency and compatibility across pipelines and applications. HMS schema evolution capabilities allow adapting to changing data structures without breaking pipelines.
- Enhanced Visibility and Discovery: HMS provides a central catalog for all your data assets, including Hudi tables. This facilitates easy discovery and exploration of data for analysts and data scientists.
Getting Started: Meeting the Prerequisites
To complete this tutorial you’ll need to get set up with some software. Here's a breakdown of what you'll need:
- Docker Engine: This powerful tool allows you to package and run applications in standardized software units called containers.
- Docker Compose: This acts as an orchestrator, simplifying the management of multi-container applications. It helps define and run complex applications with ease.
Installation: If you're starting fresh, the Docker Desktop installer provides a convenient one-stop solution for installing both Docker and Docker Compose on your specific platform (Windows, macOS, or Linux). This often proves to be easier than downloading and installing them individually.
Once you've installed Docker Desktop or the combination of Docker and Docker Compose, you can verify their presence by running the following command in your terminal:
docker-compose --versionPlease note that this tutorial was built for linux/amd64, for it to work for a Mac M2 chip, you will also need to install Rosetta 2. You can do that in a terminal window by running the following command:
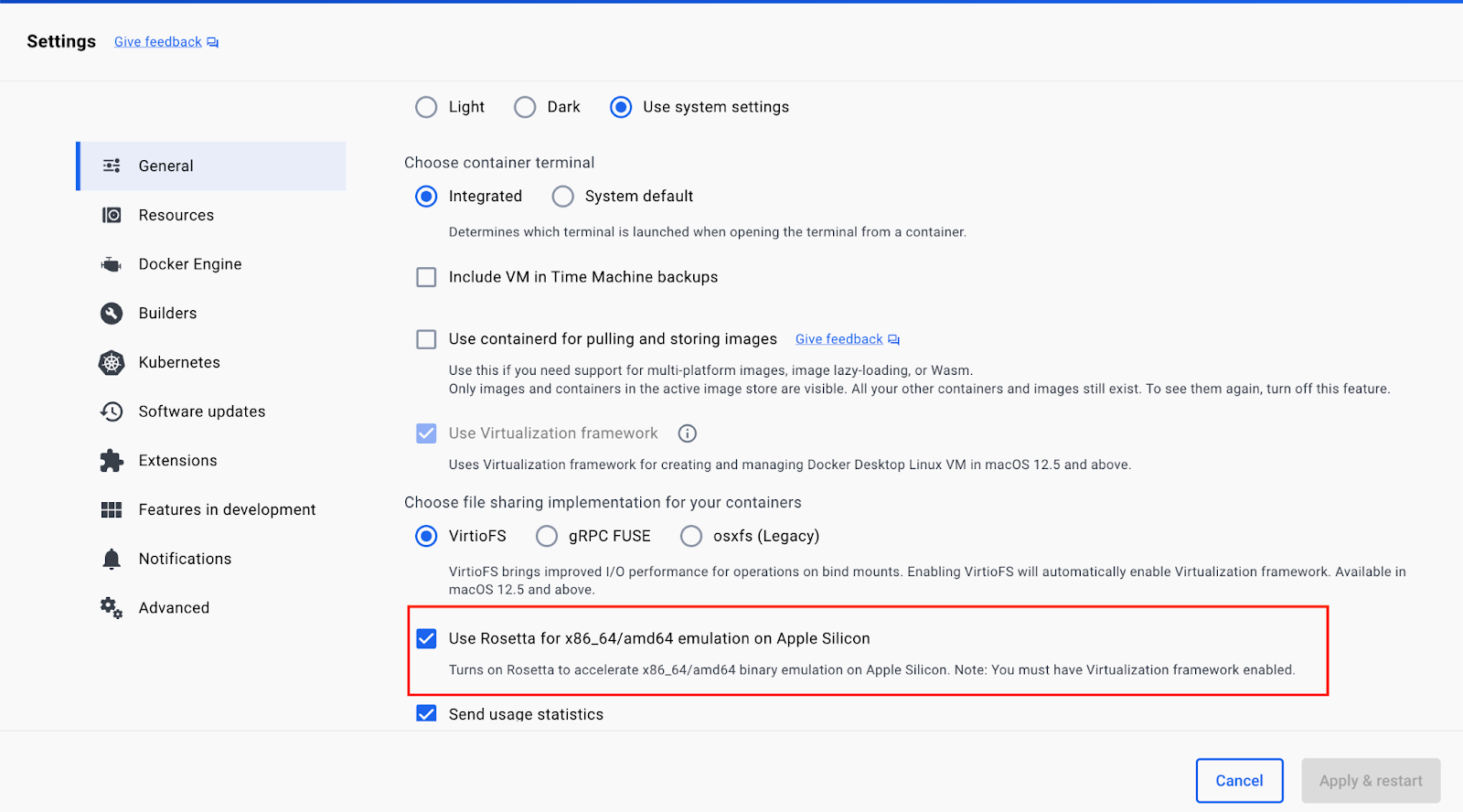
softwareupdate --install-rosettaIn Docker Desktop settings you will also need to enable using Rosetta for x86_64/amd64 binary emulation on Apple Silicone. To do that, navigate to Settings → General and then check the box for Rosetta, as shown below.
Integrating HMS with Hudi on MinIO
This tutorial uses StarRock’s demo repo. Clone the repo found here. In a terminal window, navigate to the documentation-samples directory and then hudi folder and run the following command:
docker compose upOnce you run the above command you should see StarRocks, HMS and MinIO up and running.
Access the MinIO Console at http://localhost:9000/ and log in with the credentials admin:password to see that the bucket warehouse has been automatically created.
Insert Data with Spark Scala
Run the following command to access the shell inside the spark-hudi container:
docker exec -it hudi-spark-hudi-1 /bin/bashThen run the following command, which will take you into Spark REPL:
/spark-3.2.1-bin-hadoop3.2/bin/spark-shellOnce inside the shell, execute the following lines of Scala to create a database, table and insert data into that table:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import scala.collection.JavaConversions._
val schema = StructType(Array(
StructField("language", StringType, true),
StructField("users", StringType, true),
StructField("id", StringType, true)
))
val rowData= Seq(
Row("Java", "20000", "a"),
Row("Python", "100000", "b"),
Row("Scala", "3000", "c")
)
val df = spark.createDataFrame(rowData, schema)
val databaseName = "hudi_sample"
val tableName = "hudi_coders_hive"
val basePath = "s3a://warehouse/hudi_coders"
df.write.format("hudi").
option(org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME, tableName).
option(RECORDKEY_FIELD_OPT_KEY, "id").
option(PARTITIONPATH_FIELD_OPT_KEY, "language").
option(PRECOMBINE_FIELD_OPT_KEY, "users").
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", databaseName).
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.datasource.hive_sync.partition_fields", "language").
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hive-metastore:9083").
mode(Overwrite).
save(basePath)
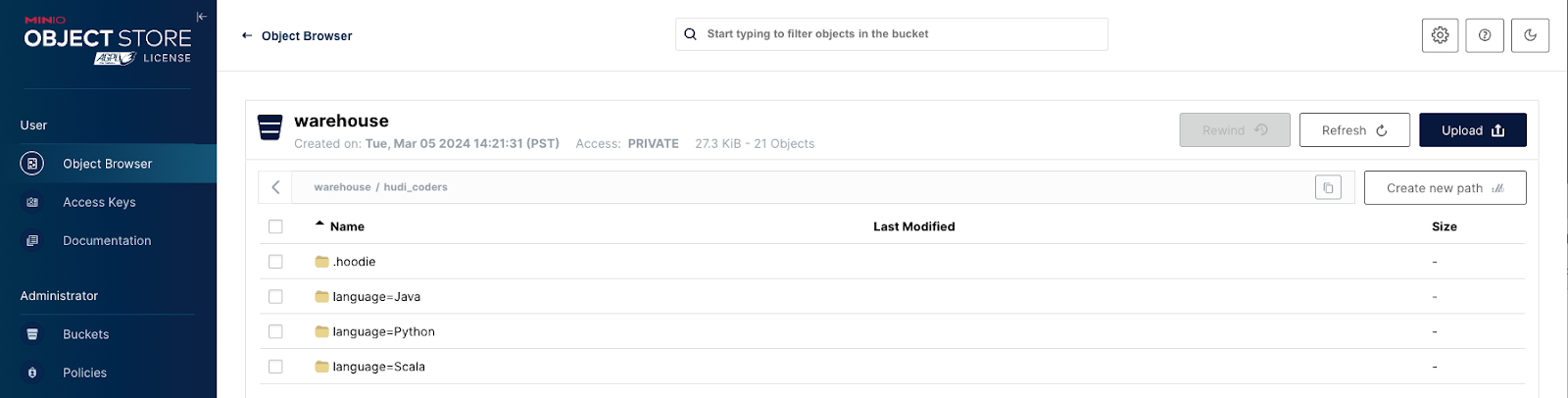
That’s it. You’ve now set up a MinIO data lake with Hudi and HMS. Navigate back to http://localhost:9000/ to see that your warehouse folder has been populated.
Data Exploration
You can optionally further explore your data by leveraging the below Scala in the same Shell.
val hudiDF = spark.read.format("hudi").load(basePath + "/*/*")
hudiDF.show()
val languageUserCount = hudiDF.groupBy("language").agg(sum("users").as("total_users"))
languageUserCount.show()
val uniqueLanguages = hudiDF.select("language").distinct()
uniqueLanguages.show()
// Stop the Spark session
System.exit(0)
Start Building Your Cloud-Native Modern Datalake Today
Hudi, MinIO, and HMS work together seamlessly to provide a comprehensive solution for building and managing large-scale modern datalake. By integrating these technologies, you can gain the agility, scalability, and security needed to unlock the full potential of your data. Reach out to us with any questions at hello@min.io or on our Slack channel.