Improve RAG Performance with Open-Parse Intelligent Chunking

If you are implementing a generative AI solution using Large Language Models (LLMs), you should consider a strategy that uses Retrieval-Augmented Generation (RAG) to build contextually aware prompts for your LLM. An important process that occurs in the preproduction pipeline of a RAG-enabled LLM is the chucking of document text so that only the most relevant sections of a document get matched to a user query and sent to an LLM for content generation. This is where Open-Parse can help. Open-Parse goes beyond naive text splitting to make sure similar text does not get split into two separate chunks. In this post, I will show how to take documents in their original form from a MinIO bucket, chunk them using Open-Parse, and then save them to another bucket that can be used to feed a vector database. The Jupyter notebook containing all the code shown in this post can be found here.
Before introducing Open-Parse’s capabilities for processing documents, let's look at the RAG inference pipeline. Pay special attention to how chunks of documents are used to improve the performance of LLMs when generating responses to a user query.
The RAG Inference Pipeline
The diagram below shows the RAG inference pipeline. It also shows the document processing pipeline, which will be discussed in later sections.
Retrieval Augmented Generation (RAG) is a technique that starts with a user request (most often a question) , uses a vector database to marry the request with additional data, and then passes the request and data to an LLM for content creation. With RAG, no training is needed because we educate the LLM by sending it relevant text chunks from a custom document corpus. This is shown in the diagram below. It works like this using a question-answering task: A user asks a question in your application’s user interface. Your application will take the question - specifically the words in it - and, using a vector database, search for chunks of text that are contextually relevant. These chunks and the original question get sent to the LLM. This entire package - question plus chunks (context) is known as a prompt. The LLM will use this information to generate your answer. This may seem like a silly thing to do - if you already know the answer (the snippets), why bother with the LLM? Remember, this is happening in real time, and the goal is to generate text - something you can copy and paste into your research. You need the LLM to create the text that incorporates the information from your custom corpus. Using RAG, user authorization can be implemented since the documents (or document snippets) are selected from the vector database at inference time. The information in the documents never becomes a part of the model's parametric parameters. The main advantages of RAG are listed below.
Advantages
- The LLM has direct knowledge from your custom corpus.
- Explainability is possible.
- No fine-tuning is needed.
- Hallucinations are significantly reduced and can be controlled by examining the results from the vector database queries.
- Document-level authorization can be implemented.

The Document Processing Pipeline
Clearly, an important part of RAG is the document processing that occurs prior to running your documents through an embedding model and saving the embeddings into a vector database. This is non-trivial if you have complex documents in a binary format, such as PDFs. For example, it is common for documents to contain tables, graphics, annotations, redacted text, and citations to other documents. Furthermore, LLMs have limits on the size of the context you can send with the original query. So, sending an entire document is not an option. Even if you could send an entire document, this may not produce the best result. A collection of snippets from several documents may be the best context for a specific user query. To solve this problem, many parsing libraries will split documents based on a desired chunk length. A brute-force way to do this is to simply split the text using only the chunk length. A better approach is to split on a sentence or paragraph boundary that still keeps the chunk under its limit. While this is better, it could put section headers in their own chunk and mangle tables, splitting them across several chunks.
Open-Parse, an open-source library for splitting PDF files, goes beyond naive text splitting. It is designed to be flexible and easy to use. It chunks documents by analyzing layouts and creating chunks based on simple heuristics that keep related text in the same chunk. Below is a flow chart showing the Open-Parse logic. Note: Text nodes get transformed to markdown while table nodes are transformed into HTML.
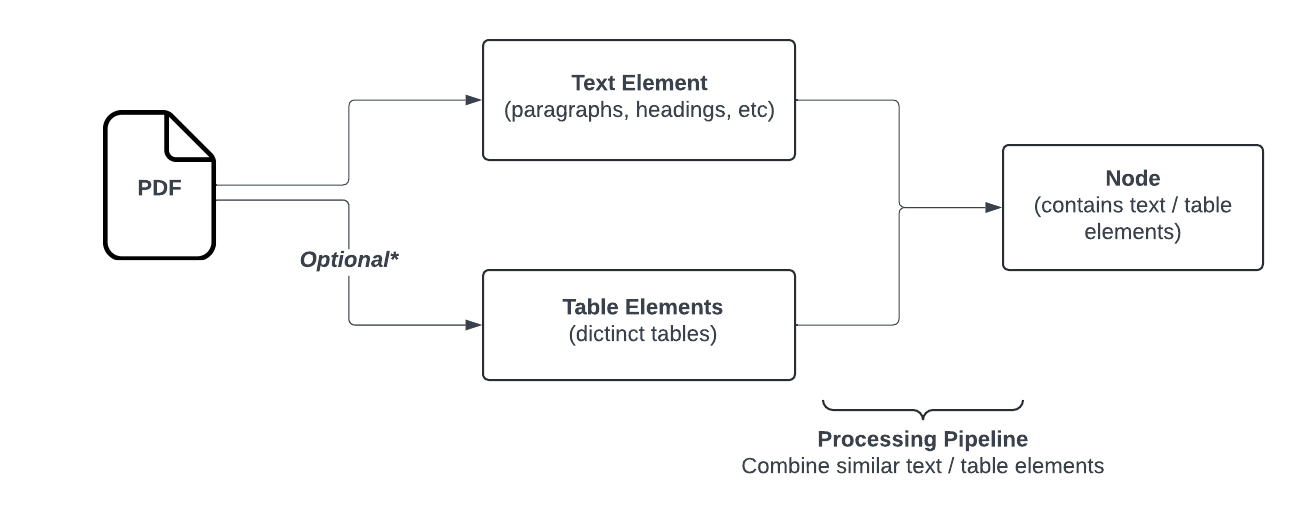
Source: https://filimoa.github.io/open-parse/processing/overview/
Let’s look at a few simple examples to see exactly what this means.
Chunking Documents with Open-Parse
In a production environment, you will want to store both the original PDFs and the chunked objects in a storage solution capable of performance and scale. This is where MinIO comes in. The code in this section assumes you have two buckets set up, as shown below.
I have uploaded a few of the sample documents used by the cookbooks in the Open-Parse repository to the original-corpus bucket. I have also uploaded a favorite white paper of mine.
The first thing we need is a utility function to download a file to a temporary directory so that open-parse can process it. The function below will connect to MinIO, and download a PDF to the system's temporary folder.
Once we run this function using the snippet below we will have a file in the temp directory of the current system.
Next, let’s split the PDF. This is as simple as a few lines of code. Once the document is split, the nodes can be displayed. This is shown below.
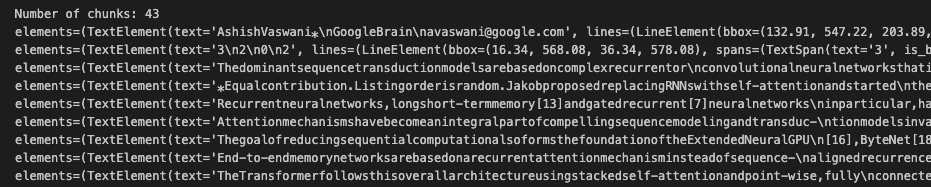
Each node contains a chunk of text and additional information about where the chunk came from. The screenshot below shows the output of the above snippet, which is quite rich in information.
Using this display technique is good for understanding the underlying object model used to represent your document. However, what is especially nice about Open-Parse is its visual tools, which can draw a bounding box over the original document showing where each chunk came from. This can be done with just two lines of code.
In this code I am asking Open-Parse to draw the original PDF as well as a bounding box around the first four chunks of text. The display is below. Notice that the authors were placed in a single chunk even though the text is in a grid-like format. Open-Parse also figured out the vertical text on the left of the page.

If we run another one of our original documents through similar code, we can see how Open-Parse handles section headers and bulleted text.

Saving Chunks to MinIO
Once we have our document chunked up, the next step is to save each chunk to MinIO. For this, we will use the document-chunks bucket shown in the screenshot above. The function below will save a file to a MinIO bucket. We will use this function to save each chunk as a separate object.
Open-Parse provides a model_dump method for serializing the chunked document to a dictionary. The snippet below calls this method and prints some additional information to give you a sense of how this dictionary is formed.
The output is shown below.
The dictionary can be pulled apart, and each chunk can be sent to MinIO. This is shown below. This code also adds metadata about the original document to each object. Saving the original filename with each chunk facilitates explainability in the Rag inference pipeline. Explainability allows an application using a RAG enabled LLM to display links to all documents used to build the prompts context. This is a powerful feature for both end users and engineers that are working to improve the performance of the inference pipeline.
Once the code above completes our document-chunks bucket will look like the following.
Next Steps
This post presented Open-Parse's core features. However, It also has several advanced features that should be explored before building a production-grade inference pipeline.
- Parsing Tables can be tricky. If the default features are having trouble processing your tables, check out the advanced table parsing features here.
- One of RAG's major advantages is explainability. It allows the user to see links to all the documents that were used to generate their answer. With Open-Parse, this is made possible by the metadata that is preserved with each document chunk. When semantically relevant chunks are collected, all the documents used can be determined, and a link to these documents can be shown along with the generated text. A short video demo of this feature can be seen here.
- Semantic chunking is an advanced technique that combines nodes (chunks) if they are semantically similar. Learn more here.
- If you wish to process the extracted data further, you can add Custom Processing functions to the DocumentParser class. Learn more here.
If you have any questions be sure to reach out to us on Slack!