Navigating the Waters: Building Production-Grade RAG Applications with Data Lakes

In mid-2024, creating an AI demo that impresses and excites can be easy. Take a strong developer, some clever prompt experimentation, and a few API calls to a powerful foundation model and you can often build a bespoke AI bot in an afternoon. Add in a library like langchain or llamaindex to augment your LLM with a bit of custom data using RAG - and an afternoon’s work might turn into a weekend project.
Getting to production, though, is another matter. You will need a reliable, observable, tunable, and performant system at scale. It will be essential to go beyond contrived demo scenarios and consider your application’s response to a broader range of prompts representing the full spectrum of actual customer behavior. The LLM may need access to a rich corpus of domain-specific knowledge often absent from its pre-training dataset. Finally, if you apply AI to a use case where accuracy matters, hallucinations must be detected, monitored, and mitigated.
While solving all these problems might seem daunting, it becomes more manageable by deconstructing your RAG-based application into its respective conceptual parts and then taking a targeted and iterative approach to improving each one as needed. This post will help you do just that. In it, we will focus exclusively on techniques used to create a RAG document processing pipeline rather than those that occur downstream at retrieval time. In doing so, we aim to help generative AI application developers better prepare themselves for the journey from prototype to production.
The Modern Data Lake: The Center of Gravity for AI Infrastructure
It’s often been said that in the age of AI - data is your moat. To that end, building a production-grade RAG application demands a suitable data infrastructure to store, version, process, evaluate, and query chunks of data that comprise your proprietary corpus. Since MinIO takes a data-first approach to AI, our default initial infrastructure recommendation for a project of this type is to set up a Modern Data Lake and a vector database. While other ancillary tools may need to be plugged in along the way, these two infrastructure units are foundational. They will serve as the center of gravity for nearly all tasks subsequently encountered in getting your RAG application into production.
A Modern Data Lake Reference Architecture built on MinIO can be found here. A companion paper showing how this architecture supports all AI/ML workloads is here.
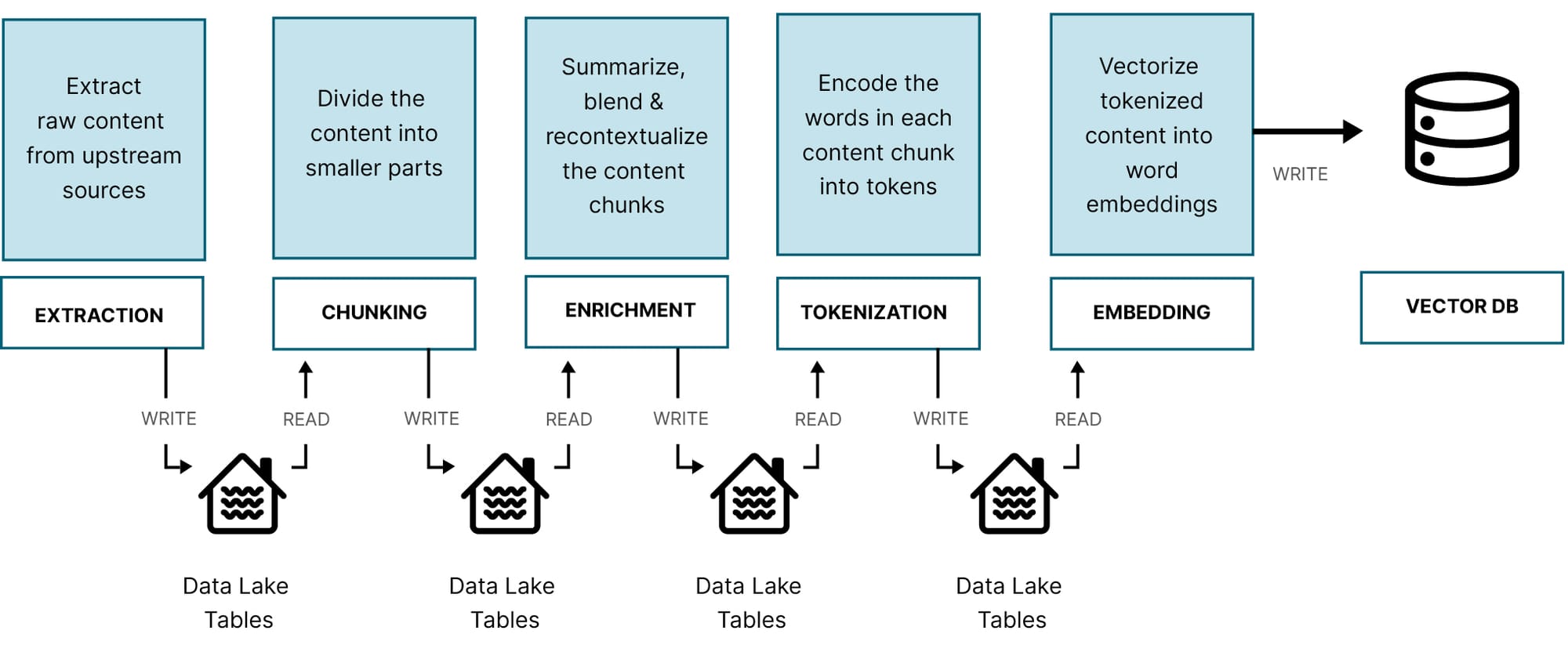
RAG: Document Pipeline Steps
Evaluation
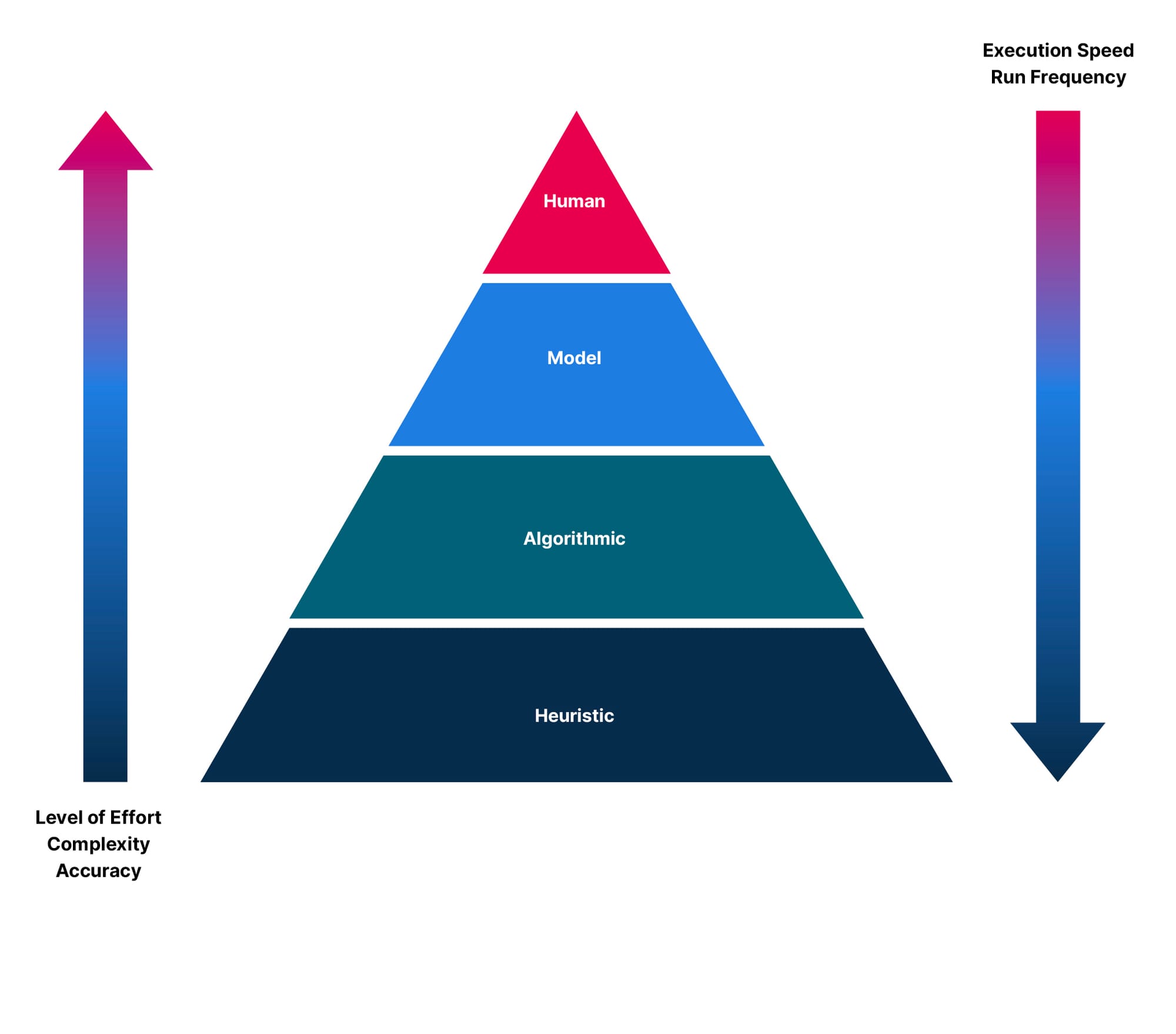
A critical early step to building a production-grade RAG application is to set up an evaluation framework - often referred to simply as evals. Without evals, you will have no way of reliably understanding how well your system is performing, knowing which components need to be tuned, or determining if you are making real progress. Additionally, evals act as a forcing function for clarifying the problem you are trying to solve. Here are some of the most common evaluation techniques:
- Heuristic Code-Based Evaluation - Scoring output programmatically using a variety of measures like output token count, keyword presence/absence, JSON validity, etc. These can often be evaluated deterministically using regular expressions and assertion libraries for conventional unit testing.
- Algorithmic Code-Based Evaluation - Scoring output using a variety of well-known data science metrics. For instance, by reframing the prompt as a ranking problem, you can use popular scoring functions from recommender systems, such as normalized discounted cumulative gain (NDCG) or mean reciprocal rank (MRR). Conversely, if a prompt can be framed as a classification problem, then precision, recall, and F1 score might be appropriate. Finally, you can use measures like BLEU, ROUGE, and semantic answer similarity (SAS) to compare the semantic output to a known ground truth.
- Model-Based Evaluation - Use one model to score the output of another as detailed in the Judging LLM-as-a-Judge paper. This technique is growing in popularity and is much cheaper than humans to scale. However, in the initial stages of moving a project from prototype to production, it can be tricky to implement reliably as the evaluator, in this case, is an LLM often subject to similar limitations and biases as the underlying system itself. Keep a close eye on this area's research, tooling, and best practices, as they are evolving quickly.
- Human Evaluation - Asking human domain experts to provide their best answer is generally the gold standard. Though this method is slow and expensive, it should not be overlooked, as it can be invaluable for gaining insight and building out your initial evaluation data set. If you want extra mileage from the work performed, you can use techniques like those detailed in the AutoEval Done Right paper to supplement your human-expert-generated evals with synthetic variations.
Along with your decision about which evaluation techniques to use, consider creating a custom benchmark evaluation dataset - generic ones typically used on Hugging Face leaderboards like the MMLU dataset won’t do. Your custom eval dataset will contain a variety of prompts and their ideal responses that are domain-specific and representative of the types of prompts your actual customers will input into your application. Ideally, human experts are available to assist with creating the evaluation dataset, but if not consider doing it yourself. If you don’t feel confident guessing what prompts are likely, just form an operating hypothesis and move forward as though it’s been validated. You can continually revise your hypotheses later as more data becomes available.
Consider applying constraints to the input prompt for each row in your eval dataset so that the LLM answers with a concrete judgment type: binary, categorical, ranking, numerical, or text. A mix of judgment types will keep your evals reasonably varied and reduce output bias. Ceteris paribus, more evaluation test cases are better; however, focusing on quality over quantity at this stage is recommended. Recent research on LLM fine-tuning in the LIMA: Less is More For Alignment paper suggests that even a small eval dataset of 1000 rows can dramatically improve output quality, provided they are representative samples of the true broader population. With RAG applications, we’ve anecdotally observed performance improvement using eval datasets consisting of dozens to hundreds of rows.
While you can start running your evals manually on an ad-hoc basis, don’t wait too long before implementing a CI/CD pipeline to automate the execution of your eval scoring process. Running evals daily or on triggers connected to source code repositories and observability tooling is generally considered an ML-ops best practice. Consider using an open-source RAG evaluation framework like ragas or DeepEval to help get you up and running quickly. Use your data lake as a source of truth for tables that contain both the versioned evaluation dataset(s) and the various output metrics generated each time an eval is executed. This data will provide valuable insight to use later in the project to make strategic and highly targeted improvements.
Data Extractors
The RAG corpus you initially start prototyping with is rarely sufficient to get you to production. You will likely need to augment your corpus with additional data on an ongoing basis to help the LLM reduce hallucinations, omissions, and problematic types of bias. This is typically done case-by-case by building extractors and loaders that convert upstream data into a format that can be further processed in a downstream document pipeline.
While there is a small risk of trying to boil the ocean by collecting more data than you need, it’s essential to be creative and think outside the box about sources of quality information your company has access to. Obvious possibilities may include extracting insights from structured data stored in your corporate OLTP and data warehouse. Sources like corporate blog posts, whitepapers, published research, and customer support inquiries should also be considered, provided they can be appropriately anonymized and scrubbed of sensitive information. It’s hard to overstate the positive performance impact of adding even small quantities of quality in-domain data to your corpus, so don't be afraid to spend time exploring, experimenting, and iterating. Here are a few of the techniques commonly used to bootstrap a high-quality in-domain corpus:
- Document Extraction - Proprietary PDFs, office documents, presentations, and markdown files can be rich sources of information. A sprawling ecosystem of open-source and SaaS tools exists to extract this data. Generally, data extractors are file-type specific (JSON, CSV, docx, etc), OCR-based, or powered by machine learning and computer-vision algorithms. Start simple and add complexity only as needed.
- API Extraction - Public and private APIs can be rich sources of in-domain knowledge. Moreover, well-designed JSON and XML-based web APIs already have some built-in structure, making it easier to perform targeted extraction of relevant properties within the payload while discarding anything deemed irrelevant. A vast ecosystem of affordable low-code and no-code API connectors exists to help you avoid writing custom ETLs for each API you wish to consume - an approach that can be difficult to maintain and scale without a dedicated team of data engineers.
- Web Scrapers - Webpages are considered semi-structured data with a tree-like DOM structure. If you know what information you are after, where it is located, and the page layout where it resides, you can quickly build a scraper to consume this data even without a well-documented API. Many scripting libraries and low-code tools exist to provide valuable abstractions for web scraping.
- Web Crawlers - Web crawlers can traverse webpages and build recursive URL lists. This method can be combined with scraping to scan, summarize, and filter information based on your criteria. On a more significant scale, this technique can be used to create your own knowledge graph.
Whatever techniques you use for data collection, resist the urge to build hacked-together one-off scripts. Instead, apply data engineering best practices to deploy extractors as repeatable and fault-tolerant ETL pipelines that land the data in tables inside your data lake. Ensure that each time you run these pipelines - key metadata elements like the source URLs and time of extraction - are captured and labeled alongside each piece of content. Metadata capture will prove invaluable for downstream data cleaning, filtering, deduplication, debugging, and attribution.
Chunking
Chunking reduces large text samples into smaller discrete pieces that can fit inside an LLM’s context window. While context windows are growing larger - allowing for stuffing more chunks of content during inference - chunking remains a vital strategy for striking the right balance between accuracy, recall, and computational efficiency.
Effective chunking requires selecting an appropriate chunk size. Larger chunk sizes tend to preserve a piece of text's context and semantic meaning at the expense of allowing fewer total chunks to be present within the context window. Conversely, smaller chunk sizes will allow more discrete chunks of content to be stuffed into the LLM’s context window. However, without additional guardrails, each piece of content risks a lower quality when removed from its surrounding context.

In addition to chunk size, you will need to evaluate various chunking strategies and methods. Here are a few standard chunking methods to consider:
- Fixed Size Strategy - In this method, we simply pick a fixed number of tokens for our content chunks and deconstruct our content into smaller chunks accordingly. Generally, some overlap between adjacent chunks is recommended when using this strategy to avoid losing too much context. This is the most straightforward chunking strategy and generally a good starting point before adventuring further into more sophisticated strategies.
- Dynamic Size Strategy - This method uses various content characteristics to determine where to start and stop a chunk. A simple example would be a punctuation chunker, which splits sentences based on the presence of specific characters like periods and new lines. While a punctuation chunker might work reasonably well for straightforward short content (i.e., tweets, character-limited product descriptions, etc) it will have apparent drawbacks if used for longer and more complex content.
- Content-Aware Strategy - Content-aware chunkers are tuned to the type of content and metadata being extracted and use these characteristics to determine where to start and stop each chunk. An example might be a chunker for HTML blogs that uses header tags to delineate chunk boundaries. Another example might be a semantic chunker that compares each sentence's pairwise cosine similarity score with its preceding neighbors to determine when the context has changed substantially enough to warrant the delineation of a new chunk.
The optimal chunking strategy for your RAG application will need to be tuned to the LLM’s context window length, underlying text structure, text length, and complexity of the content in your corpus. Experiment liberally with various chunking strategies and run your evals after each change to better understand the application performance for a given strategy. Version your chunked content in your data lake tables and be sure each chunk has lineage information to trace it back to the raw content and its respective metadata from the upstream data extraction step.
Enrichment
In many cases, the content chunks indexed for retrieval during RAG are contextually dissimilar from the actual prompts your application will encounter in production. For example, if you are building an AI question-answering bot, you may have a vast corpus of proprietary information that contains numerous correct answers to customer queries. In its raw form, however, your corpus is unlikely to be pre-organized in the format of question-answer pairs, which is ideal for similarity-based embedding retrieval. In this example, if at retrieval time, we were to naively search our corpus for chunks of raw content that are semantically similar to an inbound customer question, we may encounter suboptimal relevance of the retrieval result-set. This is a result of the fact that we are comparing the similarity of contextually disparate items - namely questions to answers. Fortunately, the solution is relatively straightforward: we can use the power of LLMs to enrich our possible answers - aka the raw content chunks - by recontextualizing them into hypothetical questions. We then index those hypothetical questions into our vector database for subsequent retrieval. This technique, called Hypothetical Document Embeddings (HyDE), illustrates the power of using LLMs to enrich your data within the document processing pipeline. Here is an example of using this technique on some content from the well-known squad_v2 dataset:
System Prompt: Given the provided snippet of text, generate three hypothetical questions that could be asked about it. Each question must be able to be answered using the information within the referenced snippet of text and only that information. Be concise.
User Prompt: “At the 52nd Annual Grammy Awards, Beyoncé received ten nominations, including Album of the Year for I Am... Sasha Fierce, Record of the Year for "Halo", and Song of the Year for "Single Ladies (Put a Ring on It)", among others. She tied with Lauryn Hill for most Grammy nominations in a single year by a female artist. In 2010, Beyoncé was featured on Lady Gaga's single "Telephone" and its music video. The song topped the US Pop Songs chart, becoming the sixth number-one for both Beyoncé and Gaga, tying them with Mariah Carey for most number-ones since the Nielsen Top 40 airplay chart launched in 1992. "Telephone" received a Grammy Award nomination for Best Pop Collaboration with Vocals.”
Response: Here are some questions that could be asked based on the provided text:
* How many nominations did Beyoncé receive at the 52nd Annual Grammy Awards?
* For which album was Beyoncé nominated for Album of the Year at the 52nd Annual Grammy Awards?
* Which song earned Beyoncé a nomination for Record of the Year at the 52nd Annual Grammy Awards?If working with a corpus composed of long-form and/or thematically complex content, consider doing additional pre-processing to pre-summarize content chunks and thus reduce their semantic dimensionality. At retrieval time, you can query the embeddings of the chunk summaries and then substitute the non-summarized text for context window insertion. This method boosts relevance when doing RAG over a large, complex, and/or frequently changing corpus.
Tokenization
Large language models in 2024 are generally transformer-based neural networks that do not natively understand the written word. Incoming raw text is converted into tokens, followed by high-dimensional embedding vectors optimized for matrix multiplication operations. This inbound process is generally called encoding. The inverted outbound process is called decoding. Many LLMs will only work for inference using the same tokenization scheme on which they were trained. Hence, it’s essential to understand the basics of the chosen tokenization strategy, as it can have many subtle performance implications.
Although there are simple character and word-level tokenization schemes, nearly all state-of-the-art LLMs use subword tokenizers at the time of writing. Consequently, we will focus only on that category of tokenizers here.
Subword tokenizers recursively break words into smaller units. This allows them to comprehend out-of-vocabulary words without blowing up the vocabulary size too much - a key consideration for training performance and the ability of the LLM to generalize to unseen texts.
A prevalent subword tokenization method used today is byte-pair encoding (BPE). At a high level, the BPE algorithm works like this:
- Split words into tokens of subword units and add those to the vocabulary. Each token represents a subword governed by the relative frequency of common adjacent character patterns within the training corpus.
- Replace common token pairs from the above step with a single token representing the pair and add that to the vocabulary.
- Recursively repeat the above steps.
BPE tokenization is generally an excellent place to start with your RAG application, as it works well for many use cases. However, suppose you have a significant amount of highly specialized domain language that is not well represented in the vocabulary of the pre-training corpus used for your chosen model. In that case, consider researching alternative tokenization methods - or exploring fine-tuning and low-rank adaptation, which are beyond this article's scope. The aforementioned constrained vocabulary issue may manifest as poor performance in applications built for specialized domains like medicine, law, or obscure programming languages. More specifically it will be prevalent on prompts that include highly specialized language/jargon. Use the eval dataset stored in your data lake to experiment with different tokenization schemes and their respective performance with various models as needed. Keep in mind that tokenizers, embeddings, and language models are often tightly coupled - so changing one may necessitate changing the others.
Conclusion
A modern data lake built on top of a MinIO object store - provides a foundational infrastructure for confidently getting RAG-based applications into production. With this in place, you can create evals and a domain-specific eval data set that can be stored and versioned inside your data lake tables. Using these evals, repeatedly evaluate and incrementally improve each component of your RAG applications document pipeline - extractors, chunkers, enrichment, and tokenizers - as much as needed to build yourself a production-grade document processing pipeline.
If you have any questions, be sure to reach out to us on Slack!