Building Modern Data Architectures with Iceberg, Tabular and MinIO


The modern data landscape demands a new breed of infrastructure – one that seamlessly integrates structured and unstructured data, scales effortlessly, and empowers efficient AI/ML workloads. This is where modern datalakes come in, providing a central hub for all your data needs. However, building and managing an effective data lake can be complex.
This blog post dives deep into three powerful tools that can optimize your current approach: Apache Iceberg, Tabular, and MinIO. The steps below will walk you through how these services seamlessly combine to create a robust, cloud-native data lake architecture specifically optimized for AI/ML workloads.
What is Tabular?
Tabular is a data platform created by the original creators of Apache Iceberg. It is designed to provide an independent, universal storage platform that connects to any compute layer, eliminating data vendor lock-in. This feature is critical to the modern data stack, it allows users to pick best-in-class compute and storage tools without being forced into a particular vendor's aged and or mismatched tool set.
In an architecture of MinIO and Iceberg and can be enhanced by Tabular. Tabular can be used to manage and query Iceberg data stored in MinIO, allowing for the storage and management of structured data in a scalable, high-performance, and cloud-native manner. These Kubernetes native, components work together smoothly with very little friction and build on each other’s capabilities to perform at scale.
Why S3FileIO instead of Hadoop's file-io?
This implementation leverages Iceberg's S3FileIO. S3FileIO is considered better than Hadoop's file-io for several reasons. Some of which we’ve already discussed elsewhere:
- Optimized for Cloud Storage: Iceberg's S3FileIO is designed to work with cloud-native storage.
- Improved Throughput and Minimized Throttling: Iceberg uses an ObjectStoreLocationProvider to distribute files across multiple prefixes in a MinIO bucket, which helps to minimize throttling and maximize throughput for S3-related IO operations.
- Strict Consistency: Iceberg has been updated to fully leverage strict consistency by eliminating redundant consistency checks that could impact performance
- Progressive Multipart Upload: Iceberg's S3FileIO implements a progressive multipart upload algorithm, which uploads data files parts in parallel as soon as each part is ready, reducing local disk usage and increasing upload speed.
- Checksum Verification: Iceberg allows for checksum validations for S3 API writes to ensure the integrity of uploaded objects, which can be enabled by setting the appropriate catalog property.
- Custom Tags: Iceberg supports adding custom tags to objects during write and delete operations with the S3 API, which can be useful for cost tracking and management.
- Avoidance of Negative Caching: The FileIO interface in Iceberg does not require as strict guarantees as a Hadoop-compatible FileSystem, which allows it to avoid negative caching that could otherwise degrade performance.
In contrast, Hadoop's S3A FileSystem, which was used before S3FileIO, does not offer the same level of optimization for cloud storage. All this to say: Don’t hobble your future-facing data lake infrastructure with the trappings of the past.
Prerequisites
Before you begin, make sure your system meets the following requirements:
If you're starting from scratch, you can install both using the Docker Desktop installer for your specific platform. It is often easier than downloading Docker and Docker Compose separately. Verify if Docker is installed by running the following command:
docker-compose --versionGetting started
To get started, clone or copy the YAML file in Tabular’s git repository. You just need the YAML for this tutorial. Feel free to explore the rest of the repository at a later time.
Breaking it Down
The provided YAML file is a Docker Compose configuration file. It defines a set of services and their configurations for a multi-container Docker application. In this case, there are two services: Spark-Iceberg and MinIO. Let's break down each section:
1. Spark-Iceberg Service:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
build: spark/
networks:
iceberg_net:
depends_on:
- rest
- minio
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
rest:
image: tabulario/iceberg-rest
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
image: Specifies the Docker image to use for the spark-iceberg service. In this case, it uses the tabulario/spark-iceberg:latest image.
depends_on: Specifies that the spark-iceberg service depends on the rest and minio services.
container_name: Assigns a specific name (spark-iceberg) to the container.
environment: Sets environment variables for the container, including Spark and AWS credentials.
volumes: Mounts local directories (./warehouse and ./notebooks) as volumes inside the container.
ports: Maps container ports to host ports for accessing Spark UI and other services.
2. Minio Service:
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: ["server", "/data", "--console-address", ":9001"]
image: Specifies the Docker image for the MinIO service.
container_name: Assigns a specific name (MinIO) to the container.
environment: Sets environment variables for configuring MinIO, including root user credentials.
ports: Maps container ports to host ports for accessing MinIO UI.
command: Specifies the command to start the MinIO server with specific parameters.
Another aspect of the MinIO service is mc, MinIO’s command line tool.
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"depends_on: Specifies that the mc service depends on the MinIO service.
image: Specifies the Docker image for the mc service.
container_name: Assigns a specific name (mc) to the container.
environment: Sets environment variables for configuring the MinIO client.
entrypoint: Defines the entry point command for the container, including setup steps for the MinIO client.
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"This sequence of commands essentially performs the following tasks:
- Removes the existing warehouse directory and its contents from the MinIO server.
- Creates a new bucket named warehouse.
- Sets the access policy of the warehouse bucket to public.
This Docker Compose file orchestrates a multi-container environment with services for Spark, PostgreSQL, MinIO. It sets up dependencies, environment variables, and commands necessary for running the services together. The services work in tandem to create a development environment for data processing using Spark and Iceberg with MinIO as the object storage backend.
Starting Up
In a terminal window, cd into the tabular-spark-setup directory in the repository and run the following command:
docker-compose upLogin into MinIO at http://127.0.0.1:9001 with the credentials admin:password to see that the warehouse bucket has been created.
Once all the containers are up and running, you can access your Jupyter Notebook server by navigating to http://localhost:8888
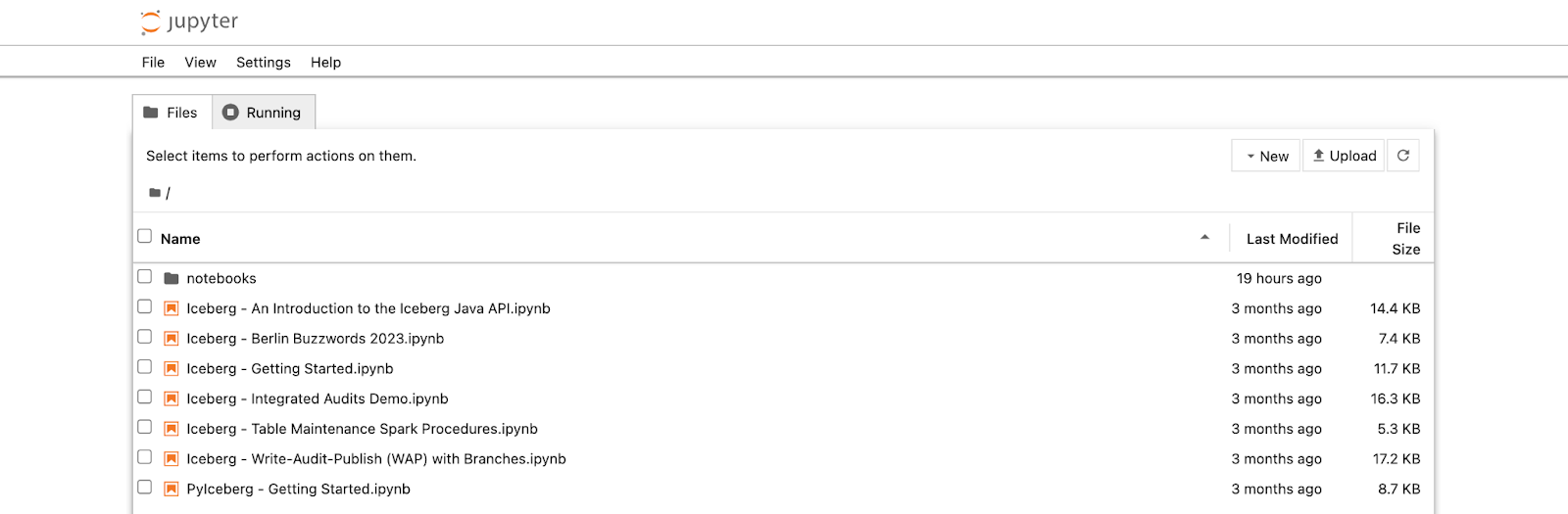
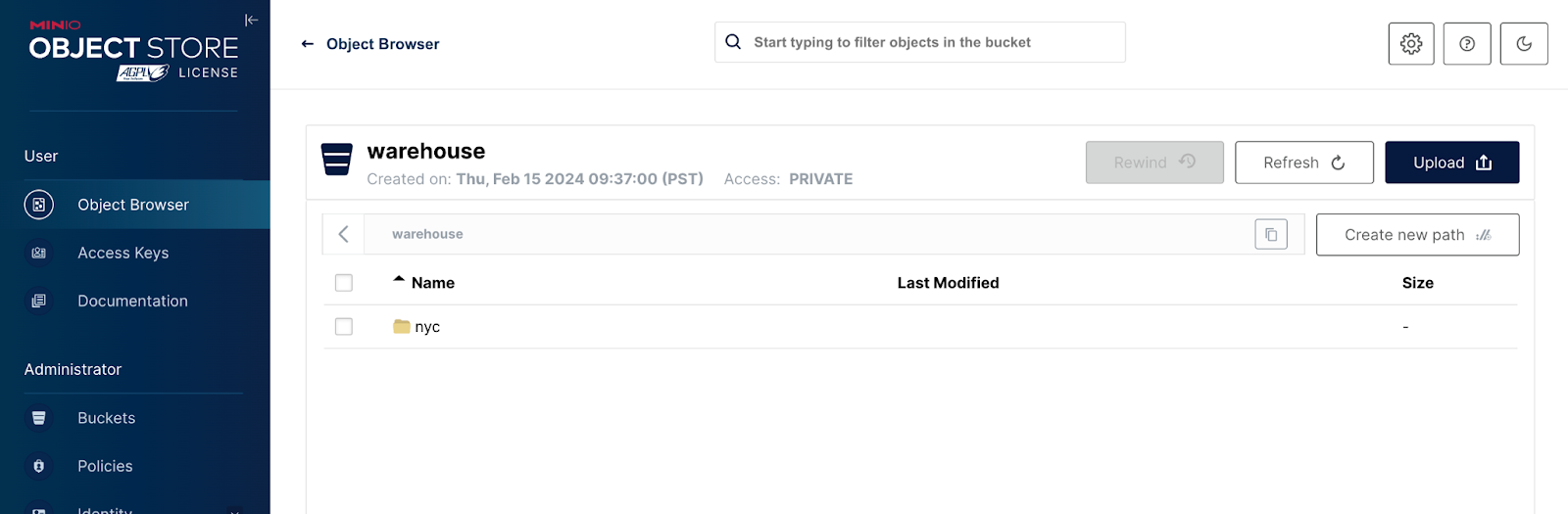
Run one of the sample notebooks and return to MinIO at http://127.0.0.1:9001 to see your warehouse populated with data.
Building Your Modern Datalake
This tutorial on building a modern datalake with Iceberg, Tabular, and MinIO is just the beginning. This powerful trio opens doors to a world of possibilities. With these tools, you can seamlessly integrate and analyze all your data, structured and unstructured, to uncover hidden patterns and drive data-driven decisions that fuel innovation. Leverage the efficiency and flexibility of this architecture in production to expedite your AI/ML initiatives and unlock the true potential of your machine learning models, accelerating your path to groundbreaking discoveries. Reach out to us at hello@min.io or on our Slack channel if you have any questions as you build.