The Architect’s Guide: A Modern Datalake Reference Architecture

An abbreviated version of this post appeared on The New Stack on March 26th, 2024.
Businesses aiming to maximize their data assets are adopting scalable, flexible, and unified data storage and analytics approaches. This trend is driven by enterprise architects tasked with crafting infrastructures that align with evolving business demands. A Modern Datalake architecture addresses this need by integrating the scalability and flexibility of a Data Lake with the structure and performance optimizations of a Data Warehouse. This post serves as a guide to understanding and implementing a Modern Datalake architecture.
What is a Modern Datalake?
A Modern Datalake is one-half Data Warehouse and one-half Data Lake and uses object storage for everything. This may sound like a marketing trick - put two products in one package and call it a new product - but the Data Warehouse that will be presented in this post is better than a conventional Data Warehouse - it uses object storage - therefore, it provides all the benefits of object storage in terms of scalability and performance. Organizations that adopt this approach will only pay for what they need (facilitated by the scalability of object storage) and if blazing speed is needed, they can equip their underlying object store with NVMe drives connected by a high-end network.
The use of object storage in this fashion has been made possible by the rise of Open Table Formats (OTFs) like Apache Iceberg, Apache Hudi, and Delta Lake, which are specifications that, once implemented, make it seamless for object storage to be used as the underlying storage solution for a data warehouse. These specifications also provide features that may not exist in a conventional Data Warehouse - for example, snapshots (also known as time travel), schema evolution, partitions, partition evolution, and zero-copy branching.
But, as stated above, the Modern Datalake is more than just a fancy Data Warehouse - it also contains a Data Lake for unstructured data. The OTFs also provide integration to external data in the Data Lake. This integration allows external data to be used as a SQL table if needed - or the external data can be transformed and routed to the Data Warehouse using high-speed processing engines and familiar SQL commands.
So the Modern Datalake is more than just a Data Warehouse and a Data Lake in one package with a different name. Collectively they provide more value than what can be found in a conventional data warehouse or a standalone data lake.
Conceptual Architecture
Layering is a convenient way to present all the components and services needed by the Modern Datalake. Layering provides a clear way to group services that provide similar functionality. It also allows for a hierarchy to be established, with Consumers on top and data sources (with their raw data) on the bottom. The layers of the Modern Datalake from top to bottom are:
- Consumption Layer - Contains the tools used by power users to analyze data. Also contains applications and AI/ML workloads that will programmatically access the Modern Datalake.
- Semantic Layer - An optional metadata layer for data discovery and governance.
- Processing Layer - This layer contains the compute clusters needed to query the Modern Datalake. It also contains compute clusters used for distributed model training. Complex transformations can occur in the Processing layer by taking advantage of the Storage Layer’s integration between the Data Lake and the Data Warehouse.
- Storage Layer - Object storage is the primary storage service for the Modern Datalake; however, MLOP tools may need other storage services such as relational databases. If you are pursuing generative AI, you will need a vector database.
- Ingestion Layer - Contains the services needed to receive data. Advanced ingestion layers will be able to retrieve data based on a schedule. The Modern Datalake should support a variety of protocols. It should also support data arriving in streams and batches. Simple and complex data transformations can occur in the ingestion layer.
- Data Sources - The data sources layer is technically not a part of the Modern Datalake solution, but it is included in this post because a well-constructed Modern Datalake must support a variety of data sources with varying capabilities for sending data.
The diagram below visually depicts all the layers described above and all the capabilities that may be needed to implement these layers. This is an end-to-end architecture where the heart of the platform is a Modern Datalake. Rather than focusing on just the processing layer and the storage layer - this architecture also shows components needed to ingest, transform, discover, govern, and consume data. The tools needed to support important use cases that depend on a Modern Datalake are also included, such as MLOps storage, vector databases, and machine learning clusters.
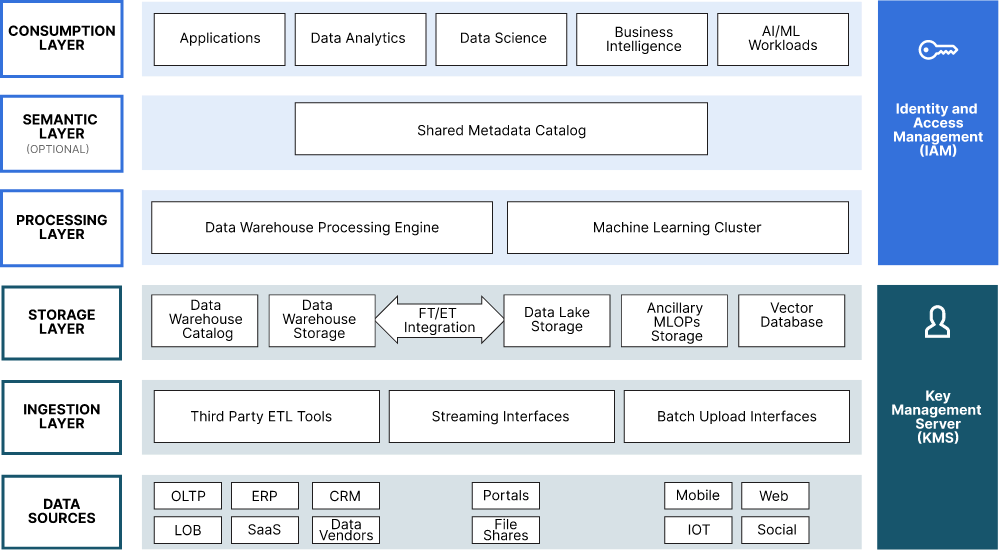
The conceptual nature of the approach used in this post is important. If the diagram above made use of product names, then meaning would be lost. Product names are rarely chosen for meaning - rather, they are chosen for brand awareness and memory retention. To this end, our conceptual architecture uses simple nouns where the feature provided is intuitive. The next section will provide an example of a concrete implementation for the reader familiar with the more popular big data projects and products in the market today. However, the reader is encouraged to refer to the conceptual diagram when making decisions for their organization.
Finally, there are no arrows. Arrows typically depict data flow and dependencies. Showing all possible data flows and dependencies would unnecessarily complicate the diagram. A better approach is to look at data flow and dependencies in the context of a use case. Once a few components are isolated in the context of a use case, then data flow and dependencies can be more clearly illustrated.
A Concrete Architecture
The purpose of this section is to ground the design of our reference architecture with concrete open-source examples. For the architect eager to dive in and start building, the projects and products shown below are free to use in a proof of concept. When your POC graduates to a funded project that will one day run in production, then be sure to check open source licenses and terms of use for all software used in your POC.
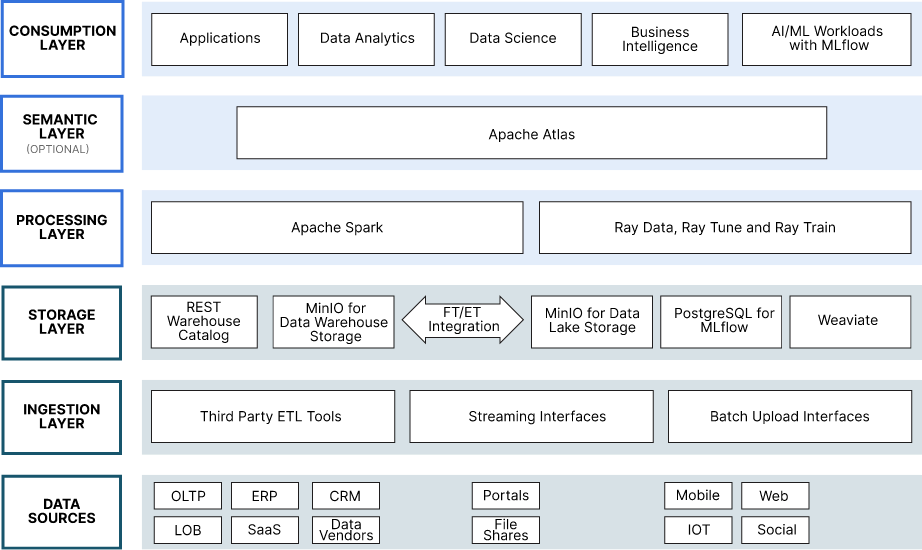
A Few Words on Data Sources
The applications, devices, and vendors that feed your Modern Datalake come in a variety of flavors, and so does their data. On-premise modern applications may be able to stream well-structured data in real time using formats such as AVRO and Parquet. On the other hand, older legacy applications may only be able to send simple files in batches, such as XML, JSON, and CSVs. Data vendors may not send data at all - expecting their customers to retrieve data.
Mobile apps, Websites, IOT Devices, and Social Media apps will typically send application logs and other telemetry (usage statistics) to your ingestion layer. Log analytics is a popular use case for a Modern Datalake. Additionally, they may send images and audio files to be used within AI/ML workloads.
Finally, organizations looking to take advantage of Generative AI will need to store documents found in file shares and portals such as SharePoint Portal Server and Confluence in the Data Lake.
The Modern Datalake needs to be able to interface with all these data sources efficiently and reliably - getting the data to either Data Lake Storage or Data Warehouse Storage. Onboarding data is the primary purpose of the Ingestion Layer of our architecture. This requires your ingestion layer to support a variety of protocols capable of receiving streamed data and batched data. Let’s investigate the components of this layer next.
The Ingestion Layer
The ingestion layer is the onramp to your Modern Datalake. It is responsible for ingesting data into the Data Storage Layer. Structured data from sources that designed their feeds for the Data Warehouse side of the Modern Datalake can bypass the Data Lake and send their data directly to the Data Warehouse. On the other hand, sources that did not design their feeds in such a fashion will need to have their data sent to the Data Lake, where it can be transformed before being ingested into the Data Warehouse.
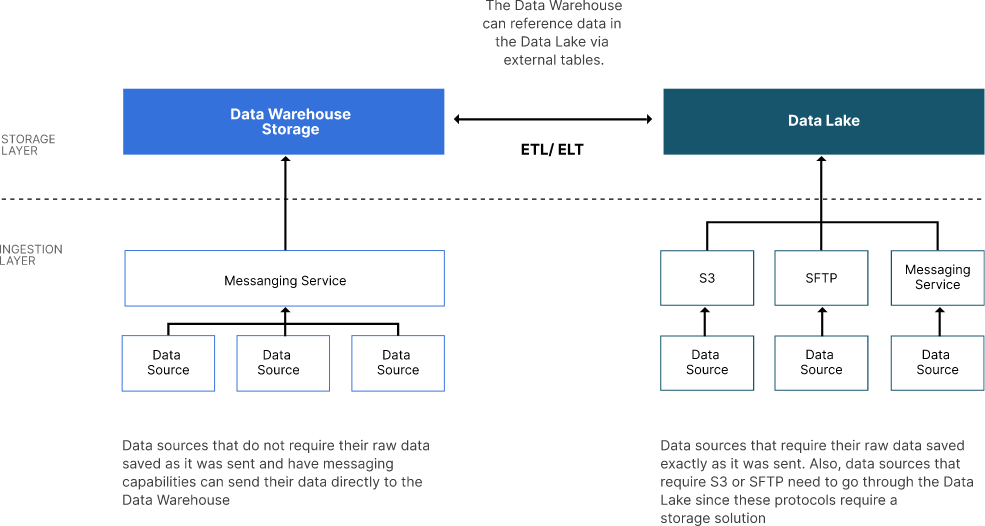
The ingestion layer should be able to receive and retrieve data. Internal Lines of Business (LOB) applications may have been given the mandate to send their data via streaming or batching. For these applications, the ingestion layer needs to provide an endpoint for receiving the data. However, Data Vendors and other external data sources may not be so willing to deliver data. The ingestion layer should also provide scheduled retrieval capabilities. For example, a data vendor may provide new datasets at the first of every month. Scheduled retrieval capabilities will allow for the ingestion layer to connect and download data at the correct time.
Streaming is the best way to transmit data to a Modern Datalake or to any destination for that matter. Steaming implies the use of a messaging service deployed in a way that makes it resilient, available and highly performant. The messaging service usually provides a queuing mechanism that acknowledges the receipt of a message only upon successful storage of the message. The service then provides “exactly once” delivery to a downstream service that is responsible for saving the data in the message to either the Data Warehouse or the Data Lake. (Note: Some message services provide “at least once” delivery requiring downstream services to implement idempotent updates to the data source. It is important to check the fine print of the service you end up using.) What is especially nice about this style of ingestion is that if the downstream service fails and does not acknowledge the successful processing of a message then the message will reappear in the queue for future ingestion. Messaging services also provide “dead letter queues” for messages that repeatedly fail.
Streaming ingestion is great, but in many cases, real-time insights are not needed. In these situations, batch or mini-batch processing works fine and can be considerably simpler to implement. For batch uploads, the S3 API is your best option. MinIO is S3 compliant, and any data source currently sending batch data to an S3 endpoint will work “as-is” with only a connection change once you switch over to the MinIO Data Lake. However, many organizations may still prefer FTP/SFTP for its simplicity and ability to run in highly constrained environments. MinIO also has support for FTP and SFTP. This interface allows a data source to send data to MinIO the same way it would send data to an FTP server. From an application or users perspective, moving data onto MinIO using SFTP is seamless since everything is essentially the same - from policies, security, etc.
The Data Storage Layer

The Data storage layer is the bedrock that all other layers depend upon. Its purpose is to store data reliably and serve it efficiently. There will be an object storage service for the Data Lake side of the Modern Data Lake and there will be an object storage service for the Data Warehouse.

These two object storage services can be combined into one physical instance of an object store if needed by using buckets to keep data warehouse storage separate from data lake storage. However, consider keeping them separate and installed on different hardware if the processing layer will be putting different workloads on these two storage services. For example, a common data flow is to have all new data land in the Data Lake. Once in the Data Lake, it can be transformed and ingested into the Data Warehouse, where it can be consumed by other applications and used for the purpose of Data Science, Business Intelligence, and data analytics. If this is your data flow, then your Modern Datalake will be putting more load on your Data Warehouse, and you will want to make sure it is running on high-end hardware (storage devices, storage clusters, and network).
External table functionality allows Data Warehouses and processing engines to read objects in the Data Lake as if they were SQL tables. If the Data Lake is used as the landing zone for raw data, then this capability, along with the Data Warehouse SQL capabilities, can be used to transform raw data before inserting it into the Data Warehouse. Alternatively, the external table could be used “as-is” and joined with other tables and resources inside the Data Warehouse without it ever leaving the Data Lake. This pattern can help save on migration costs and can overcome some data security concerns by keeping the data in one place while, at the same time, making it available to outside services.
Most MLOP tools use a combination of an object store and a relational database to support MLOps. For example, an MLOP tool should store training metrics, hyperparameters, model checkpoints, and dataset versions. Models and datasets should be stored in the Data Lake, while metrics and hyperparameters will be more efficiently stored in a relational database.
If you are pursuing Generative AI, you will need to build a custom corpus for your organization. It should contain documents with knowledge that no one else has and only documents that are true and accurate should be used. Furthermore, your custom corpus should be built with a Vector Database. A vector database indexes, stores, and provides access to your documents alongside their vector embeddings, which are numerical representations of your documents. Vector Databases facilitate semantic search, which is needed for Retrieval Augmented Generation - a technique utilized by generative AI to marry information in your custom corpus to an LLMs trained parametric memory.
The Processing Layer
The processing layer contains the compute needed for all the workloads supported by the Modern Datalake. At a high level, compute comes in two flavors: Processing engines for the Data Warehouse and clusters for distributed machine learning.

The Data Warehouse processing engine supports the distributed execution of SQL commands against the data in Data Warehouse storage. Transformations that are part of the ingestion process may also need the compute power in the processing layer. For example, some Data Warehouses may wish to use a medallion architecture - others may choose a star schema with dimensional tables. These designs often require substantial ETL against the raw data during ingestion.
The Data Warehouse used within a Modern Datalake disaggregates compute from storage. So, if needed, multiple processing engines can exist for a single Data Warehouse data store. (This differs from a conventional relational database where compute and storage are tightly coupled, and there is one compute resource for every storage device.) A possible design for your processing layer is to set up one processing engine for each entity in the consumption layer. For example, a processing cluster for business intelligence, a separate cluster for data analytics, and yet another for data science. Each processing engine would query the same Data Warehouse storage service - however, since each team has their own dedicated cluster they do not compete with each other for compute. If the Business Intelligence team is running month-end reports that are compute-intensive, then they will not interfere with another team that may be running daily reports.
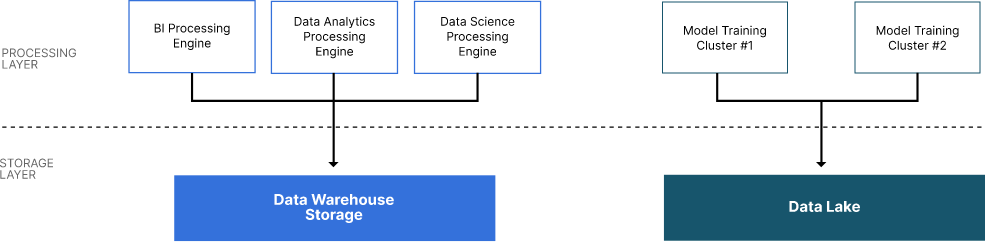
Machine Learning models, especially Large Language Models, can be trained faster if training is done in a distributed fashion. The Machine Learning Cluster supports distributed training. Distributed training should be integrated with an MLOPs tool for experiment tracking and checkpointing.
The Optional Semantic Layer
A semantic layer helps the business understand its data. The semantic layer sits between the processing layer, which serves up the data from the storage layer, and the Consumption layer, which contains the tools and applications looking for data. It acts like a translator that bridges the gap between the language of the business and the technical terms used to describe data. It also helps both data professionals and business users find relevant data for either end-user reports or dataset creation for AI/ML.
In its simplest form, the Semantic layer could be a data catalog or an organized inventory of data. A data catalog typically includes the original data source location (lineage), schema, short description, and long description. A more robust Semantic layer can provide security, privacy, and governance by incorporating policies, controls, and data quality rules.
This layer is optional. Organizations that have few data sources with well-structured feeds may not need a semantic layer. A well-structured feed is a feed that contains intuitive field names and accurate field descriptions that can be easily extracted from data sources and loaded into the Data Warehouse. Well-structured feeds should also implement data quality checks at the source so that only quality data is transmitted to the Modern Datalake.
However, large organizations that have many data sources where metadata was an afterthought when schemas and feeds were designed should consider implementing the semantic layer. Many of the products that can be used in this layer provide features that help an organization populate a metadata catalog. Also, organizations that operate in complex industries should consider a semantic layer. For example, industries like Financial Services, Healthcare and Legal make heavy use of terms that are not everyday words. When these domain-specific terms are used as table names and field names, the underlying meaning of the data can be hard to ascertain.
The Consumption Layer
Let’s conclude our presentation of the Modern Datalake layers by looking at the workloads run in the topmost layer, the Consumption Layer, and discussing how the layers below support their specific use cases. Many of the workloads below are often used interchangeably or synonymous - this is unfortunate because when investigating their needs, it is better to have precise definitions. In the discussion below, I will precisely describe each function and then align it with the capabilities of the Modern Datalake.
Applications - Custom applications can programmatically send SQL Queries to the Modern Datalake to provide custom views for end users. These may be the same applications that submitted raw data as data sources at the bottom of the diagram. A use case that should be supported by a Modern Datalake is to allow applications to submit raw data, clean it, combine it with other data and finally serve it up quickly. Applications may use models trained with data from the Modern Datalake. This is another use case that the modern Datalake should support. Applications should be able to send raw data to the Modern Datalake, get it processed, and sent to model training pipelines - from there, the models can be used to make predictions within the application.
Data Science is the study of data. Data scientists design the datasets and potentially the models that will be trained and used for inference. Data scientists also use techniques from mathematics and statistics for the purpose of feature engineering. Feature engineering is a technique for improving datasets used to train a model. A very slick feature that Modern Datalakes possesses is Zero-copy branching, which allows data to be branched the same way code can be branched within a Git repository. As the name suggests, this feature does not make a copy of the data - rather, it makes use of the metadata layer of the open table format used to implement the Data Warehouse to create the appearance of a unique copy of the data. Data scientists can experiment with a branch - if their experiments are successful, then they can merge their branch back into the main branch for other data scientists to use.
Business Intelligence is often retrospective, providing insights into past events. It involves the use of reporting tools, dashboards, and key performance indicators (KPIs) to provide a view into business performance. Much of the data needed for BI are aggregations which can require a fair amount of compute to create.
Data analytics, on the other hand, involves the analysis of data to extract insights, identify trends, and make predictions. It is more forward-looking and aims to understand why certain events occurred and what might happen in the future. Data analytics overlaps Data Science in that it incorporates statistical analysis and machine learning techniques.
Machine Learning - the machine learning workload is where ML teams run their experiments and MLOPs teams test and promote models to production. There is often a considerable difference between the needs of teams that are using machine learning for research and prototyping vs. those that are putting models into production on a regular basis. Teams only doing research and experimental work can often get away with minimal ML-Ops tooling, whereas those putting models into production will need considerably more rigorous tools and processes.
Security
The Modern Datalake must provide authentication and authorization for users and services. It should also provide encryption for data at rest and data in motion. This section will look into these aspects of security.
Both the Data Lake and the Data Warehouse must support an Identity and Access Management (IAM) solution that facilitates authentication and authorization. Both halves of the Modern Datalake should use the same directory service for keeping track of users and groups allowing users to present their corporate credentials when signing into the user interface for both the Data Lake and the Data Warehouse. For programmatic access, since each product requires a different connection type, the credentials that need to be presented for authentication will be different. Likewise, the policies used for authorization will also be different as the underlying resources and actions are different. The Data Lake requires authorization for buckets and objects as well as bucket and object actions. The Data Warehouse, on the other hand, needs tables and table related actions to be authorized.
Data Lake Authentication - Every connection to the Data Lake requires verification of identity and the Data Lake should integrate with the organization's identity provider. Since the data lake is an object store that is S3 compliant, the AWS Signature Version 4 protocol should be used. For programmatic access, this means that each service wishing to access an administrative API or an S3 API, such as PUT, GET, and DELETE operations, must present a valid access key and secret key.
Data Lake Authorization - Authorization is the act of restricting the actions and resources the authenticated client can perform on the Data Lake. An S3-compliant object store should use Policy-Based Access Control (PBAC), where each policy describes one or more rules that outline the permissions of a user or group of users. The Data Lake should support S3-specific actions and conditions when creating policies. By default, MinIO denies access to actions or resources not explicitly referenced in a user’s assigned or inherited policies.
Data Warehouse Authentication - Similar to the Data Lake, every connection to the Data Warehouse must be authenticated and the Data Warehouse should integrate with the organization’s identity provider for authenticating users. A Data Warehouse may provide the following options for programmatic access: ODBC connection, JDBC connection, or REST session. Each will require an access token.
Data Warehouse Authorization - A Data Warehouse should support User, Group, and Role level access controls for tables, views, and other objects found in the Data Warehouse. This allows access to individual objects to be configured based on either the user’s id, a group, or a role.
Key Management Server - For security at rest and in transit, the Modern Datalake uses a Key Management Server (KMS). A KMS is a service that is responsible for generating, distributing, and managing cryptographic keys used for encryption and decryption.
Summary
There you have it, the five layers of a Modern Datalake from data sources to consumption. This post explored a conceptual reference architecture for Modern Datalakes. The goal - to provide organizations with a strategic blueprint for building a platform that efficiently manages and extracts value from their vast and diverse data sets. The Modern Datalake combines the strengths of traditional data warehouses and flexible data lakes, offering a unified and scalable solution for storing, processing, and analyzing data. If you would like to go deeper with the team at MinIO on what components are recommended, feel free to reach out to us at hello@min.io.